新しい環境を求めて LaTeX の編集環境を
Sublime Text 2に移行しましたが,Sublime Text 3 がいつまでもβ版だったりして停滞感があるところで
Atom が流行してきたので,そっちに移行していました.
当初は完成度が低くて実用的ではなかったのですが,最近(2016年1月頃)は実用にギリギリ耐える気がしてきたので,設定や注意事項をメモしておきます.
TeXのインストール
多くの方のご尽力により,世界でも標準的な
TeX Live をインストールすれば日本語でも不自由しないので,これを使っています.以下でも TeX Live で普通にインストールした環境を前提としています.
何かとTeX関連のバイナリにパスが通っていることを前提としているパッケージが多いので,
C:\texlive\2015\bin\win32
を環境変数Pathに追加してください.
(上記はTeX Live 2015を既定の設定でインストールしたときのパスですが,バージョンなどに合わせて適宜読み替えてください.)
Atomのインストール
Atomのホームページからインストールできます. 最近は標準的なインストールで日本語が問題なく使えます.ただ,後述しますがフォントの設定はした方がよいように思います.
シンタックスハイライティング
文法に応じて色付けするあれです
をインストールします.なお,Atomでのパッケージの検索とインストールは File メニューの Settings で設定のタブを開き,Install を選んで表示される画面から行うことができます.
Latexmkによる自動コンパイル
一応ビルド用のパッケージがあるのですが,日本語原稿と英語原稿で設定を切り替えたりするのが面倒なのと,TeXのエラーメッセージは機械可読性がいまいちで完全にエラーハンドリングできることを期待できないので,最近はエディタのパッケージでビルドを行うのではなくlatexmkで常時自動コンパイル状態にしています.
latexmkrcファイルの準備
文書ごとにフォルダを用意し,TeXのソースを格納しているフォルダに日本語の場合は以下のような latexmkrc ファイル(ファイル名の頭にドットはついていません)
英語の場合は以下のような latexmkrc ファイル
を配置して,TeXのソースを格納しているフォルダで開いたコマンドプロンプトで
latexmk -pvc
を実行しておけばTeXのソース(やbibファイルや図のファイル)が更新されるたびに自動でコンパイルしてくれます.自動でビューワーの起動も行うのですが,後述の Atom内PDFビューワーを使う場合は不要なので設定ファイル内のコメントのように exit か何かを指定しておくとよいと思います.ビューワーを起動しないでコンパイルだけするオプションは無いような気がします.
また,この場合TeXソースがあるフォルダまでCDするのは面倒なので
- エクスプローラーでシフトキーを押しながら右クリックするとメニューに密かに「このフォルダでコマンドプロンプトを開く」という項目が増えているので,これを使う.
- atom-terminal パッケージをインストールすると,atom 左側の tree-view でフォルダや右クリックした際に表示されるメニューに Open terminal at root が追加されるのでこれを使う.
などの方法を覚えておくと便利だと思います.
エラーの確認
エラーは.logファイルに出力されています.後述するPDFファイルのタブとともにAtomで開きっぱなしにしておいても順次更新されるので,僕は開きっぱなしにしています.なお,logファイルを色付けして表示するためには Grammar を LaTeX Log に設定する必要があります..log ファイルを開いた状態で右下に Plain Text と表示されているので,これをクリックすると Grammar を選択することができます..logの拡張子で自動的にGrammarを変えることも可能でしょうが,LaTeX以外でも.logの拡張子を持つファイルがあるので特に設定していません.
備考
ファイル名の頭にドットがついた .latexmkrc をホームフォルダ(WindowsではHOME環境変数で指定したフォルダか C:\Users\maruta とかになっていると思います)に配置すると latexmk はデフォルトでその設定を使ってくれますが,昔のTeXソースをコンパイルするときの設定を忘れたり英語原稿と日本語原稿で記述を変えたりするのが面倒なので,TeXの原稿ごとに設定ファイルを配置するこの形に落着きました.
Atom内でのPDFプレビュー(+SyncTeX)
実は大してメリットがない気もしますが,AtomのタブでPDFを開けるとなんかカッコいいです.
をインストールするとこれが実現でき,表示されたPDFをクリックした際に対応箇所のTeXソースに飛ぶSyncTeXを利用することができます.
日本語PDF問題
長らく標準では日本語のPDFが文字化けしていました.これに関してIssueがあったものの途中で止まっていたのですが,調べてみたところ解決できそうでしたのでお願いして直してもらいました.
バージョン 0.39.0 以降では日本語が利用可能です.Issueを作成された@yohasebeさんと開発者の@izuzakさんに感謝いたします.
PDFへのフォント埋め込み設定
Atom の pdf-view パッケージではフォントを埋め込んでいないPDFファイルの漢字には中国語フォントが適用されるようです.ひらがなに使われる日本語フォントとの組み合わせと相まって日本語の文書は大変見苦しくなりますので,何らかのフォントの埋め込みをお勧めします.
TeX Live のコマンドプロンプトで
kanji-config-updmap status
を入力して状況を確認し
kanji-config-updmap ipaex
などのコマンドで埋め込むフォントを選択することができます.
pdf-view の現状の課題
ここまで書いておいてなんですが,100ページくらいのPDFを開くと簡単に不具合を起こしたり,テキストが選択できなかったり検索がかからなかったりするのであまり使い勝手が良いわけではありません(2016年1月現在).今後の進化に期待です.
SumatraPDFでのPDFプレビュー(+SyncTeX)
Atomの外部でPDFをプレビューする場合,いわゆる Acrobat や Reader でPDFファイルを開くとPDFファイルがロックされてTeXのコンパイルができなくなるので,コンパイルのたびにビューワーを閉じないといけませんが,PDFファイルをロックしない SumatraPDF を使うと,PDFを開いたまま修正とコンパイルを行うことができます.SumatraPDFは
からダウンロード可能です.
またビューワー上でクリックした際にTeXソースの該当箇所に自動で移動する SyncTeX については,上述の latexmkrc 内での指定のような -inverse-search オプションを付けて起動するか,適当な(TeXで生成された)PDFを開いた状態でSumatraPDFの左上のアイコンをクリックして表示されるメニューから Settings → Options をクリックし,Set inverse search command-line の項目を
"C:\Users\maruta\AppData\Local\atom\bin\atom.cmd" "%f:%l"
のように設定してください.
atomの実行ファイルはユーザー毎のフォルダにインストールされているので,どの場合も実行ファイルのパス中に含まれる maruta を自分のユーザー名で置き換えることに注意してください.
スペルチェッカの設定
Atomには標準でスペルチェッカがついています.が,Windows の場合
- Windows 標準のスペルチェッカが使われる
- 言語はシステムの設定に準じる
という仕様になっているで,英語のスペルチェッカを使うためにはシステムの言語設定を英語に切り替えるしかありません.この辺の仕様については色々と議論があるので,
そのうち改善するような気もしますが,今のところAtomでLaTeXを使う上で最大の問題かもしれません.LaTeX編集中にスペルチェッカを有効にするためには
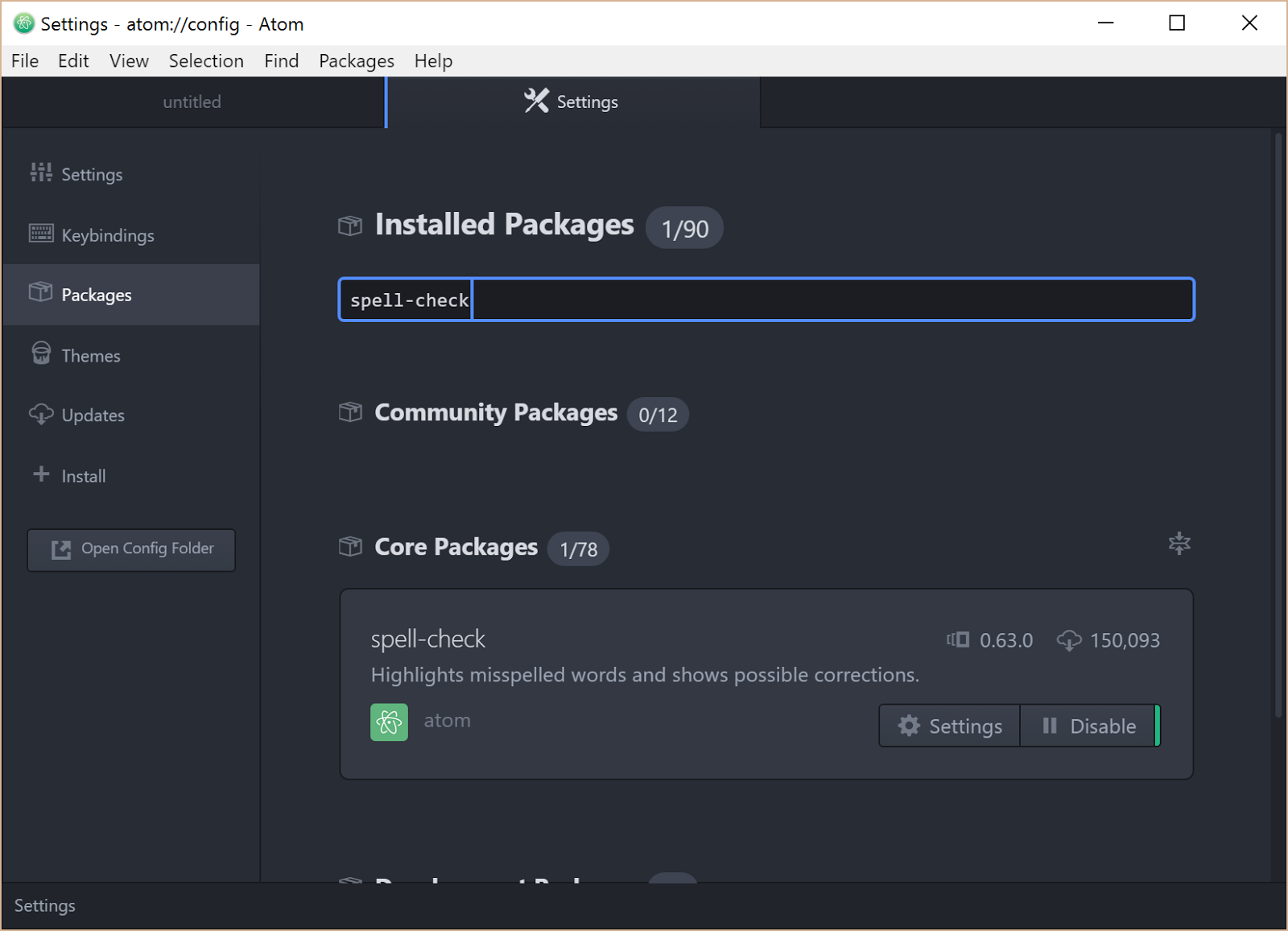
[File]-[Setting]でPackagesの画面を開き,spell-checkを検索します
そしてspell-checkパッケージの設定画面(Settings)に移動し,Grammarsの項に text.tex.latex を追加します.
フォントの設定
File メニューから Settings の画面を開き Font Family のところに CSS でフォントを指定する要領で書くことができます.僕の設定は
Consolas, メイリオ
です.カンマで区切って列挙すると最初のフォントに含まれない文字は次のフォントで表示される感じになるので,簡単に好きな英文フォントと和文フォントを組み合わせることができます.個人的には,ここの簡単さとフォントのレンダリングがWebブラウザ並みに綺麗という点が LaTeX 編集に Atom を使う最大のアドバンテージな気がします.
僕は日本語を書くときには等幅を妥協する派ですが,等幅フォントが好きな人は
Miguフォントとかを使うと良いと思います.
覚えておくべき機能
スニペット Snippet
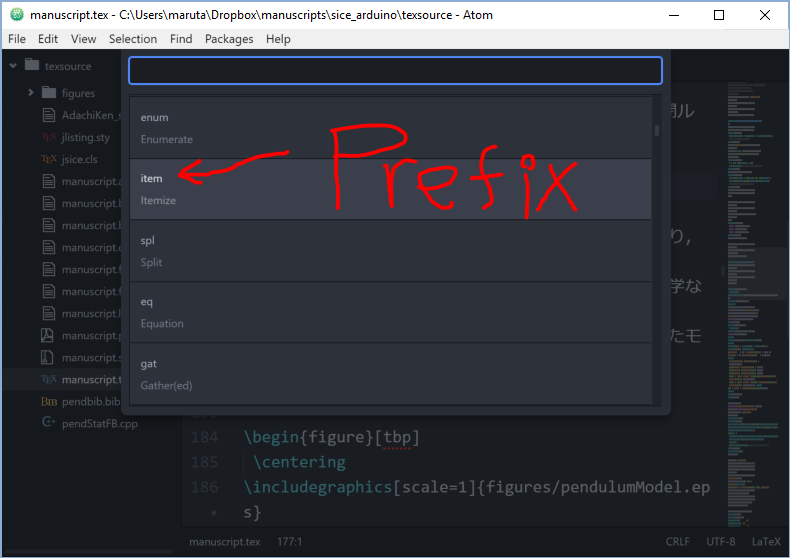
今どきのエディタの定番機能で,定型コードの入力を大幅に省力化できます.とりあえず language-latex パッケージをインストールした際にLaTeX用のスニペットが登録されているので,適当なTeXファイルを開いて[Alt]+[Shift]+[S]のショートカットを使うと一覧を見ることができます.
この一覧から使いたい項目を選択することもできますが,項目の上側に表示されているprefixを覚えておけば,通常の文と同様にprefixを入力し[TAB]を押すことでスニペットを使うことができます.
文脈によって(数式環境の中とか外とか)有効なスニペットが変わったりするので色々試してみてください.
使い方に慣れてきたらスニペットの自作をお勧めします.
マルチカーソル
これまた今どきのエディタでは定番の,複数のカーソルを使って複数の箇所を同時に編集する機能です.
- [Ctrl]キーを押しながらクリックするとその位置にカーソルが増えます.
- 適当な文字列を選択した状態で[Ctrl]+[D]を入力すると,選択中の文字列を検索してその位置にカーソルが増えます.繰り返し[Ctrl]+[D]を入力することで順次検索&カーソルの追加が行われます.
慣れるとすごく便利なのでぜひ使うように心がけてみてください.
LaTeXの編集作業の中では,表や数式をいじるときに使いどころが多いと思います.
便利なパッケージなど
アイコンの拡充
をインストールするとファイルのアイコンが豊富になります.TeXのファイルも専用のアイコンになり,ツリー表示やタブが少しわかりやすくなるのでインストールをお勧めします.
minimap
今どきのエディタによくあるカッコいいあれです.
標準では入っていないですが
をインストールすると使えるようになります.
ファイル名補完
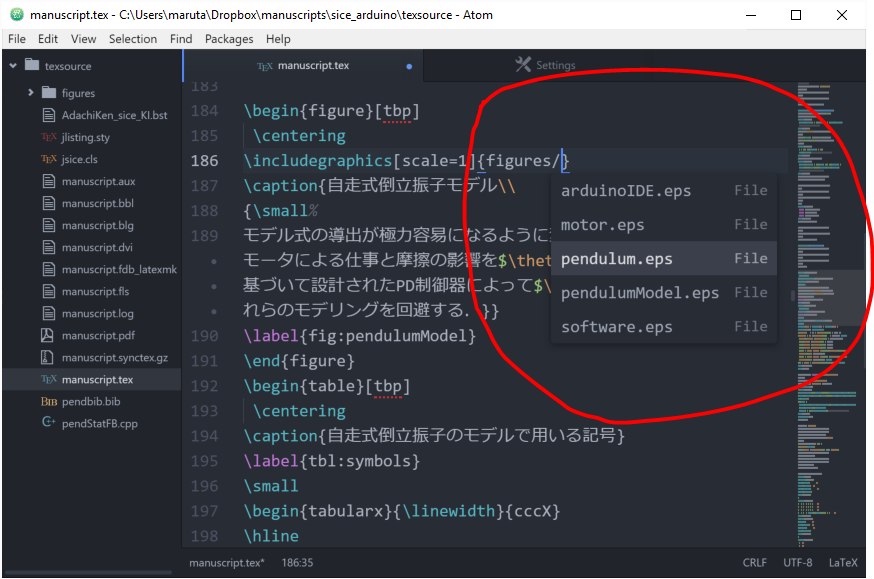
LaTeXで図や写真・画像などを使う場合,ファイル名を入力するのが地味に面倒だったりしますが,
を使うと補完の候補にファイルやフォルダの名前が出現するようになります.
カレントディレクトリ配下のファイル名を入力したい場合「./」と入力を始めると候補が表示されます.
\cite, \ref の補完
参考文献や数式,図表の番号を参照する際に
を入れておくと自動で補完してくれて快適です.参考文献については .bib ファイルを読み込んでいるので,BibTeXを使っていない場合は機能しないと思います.
まとめ
Atomはオープンソースの申し子のようなエディタであり,これまでの急速な改善からみても,いまどきの定番エディタの地位を長く維持できるような気がします.
ただし LaTeX や Windows や日本語といった辺境領域への対応はまだまだ不安定だったり完成度が低い感じですので,これからさらに開発が盛り上がることを期待したいです.
自分でもちょいちょいと貢献できたらな~と考えています.
あと,個人的には SublimeText2でだいぶお世話になり,最近 Atom 版の開発が始まったLaTeXTools に期待しています.
いまのところ動かない機能が8割といった感じなので(2016年1月現在),頃合いをみて試してみたいと思います.